DDD North 2014 In Review

This past Saturday, 18th October 2014, saw another DDD (Developer, Developer, Developer) event. This one was the 4th annual DDD North event, this year held at the University Of Leeds.

After arriving and signing in, I proceeded through the corridors to the communal area where we were all greeted with a cup of coffee (or tea) and a nice Danish pastry! It’s always a nice surprise to get a nice cake with your morning coffee, so although I wasn’t really hungry as I’d recently eaten a large breakfast, I decided that a Danish Pastry covered in sweet, sweet icing was too much of a temptation to be able to refuse!

After this delightful breakfast, I headed down the corridor for the first of the day’s sessions.
The first session of the day is Liam Westley’s “An Actor’s Life For Me” which talks about parallel processing with multiple threads using the Task Parallel Library and utilising the Actor Model. Liam introduces the Actor model and states it was first described by Carl Hewitt as early as 1973. The dilemma we have for parallel processing is due to shared state, causing us to lock around areas of memory where multiple threads may try to access that state. The Actor model solves this by not having shared state within the system, instead having each process take stateless data that is not shared and outputting stateless data to the next process in the processing pipeline. Liam uses an analogy of making a cup of tea and the steps involved in that whilst also getting an itch that needs scratching whilst making that cup of tea. The itch (and thus the scratch) can happen during any of the tea-making steps, thus increasing the combinations of how alternating between making tea and scratching can grow exponentially.

Liam talks about how CPU’s have been multi-threaded and multi-core for many years now, first arriving around the same time as .NET v1.0, whilst in the same time frame, our developer tools haven’t really kept up. .NET 1.0 pretty much gave us raw access to how windows handles threads using the TheadPool, which meant managing multiple threads and sharing state between them was very difficult. .NET 2.0 gave us a SynchronizationContext, but multi-threaded programming was still very hard. Eventually, we got the much simplified Async & Await keywords, but now we have the Task Parallel Library which provides us with the Actor pattern. This basically allows us to write our code in individual “blocks” which are essentially black boxes sharing no state with any other block. We can then chain these blocks together into a processing pipeline, giving us the ability to perform some computational process without sharing state.
Liam then shows us a demo of a console application which produces an MD5 hash for a number of large files in a folder. The first iteration of the demo shows this happening without using the Task Parallel Library (TPL) and so performs no parallel processing and simply processes each file, one at a time on a single thread, taking some time to complete. The second iteration Liam shows us uses the TPL, but still only works in a single-threaded manner by wrapping the hash calculation function as a TPL ActionBlock. This iteration does the same as the single-threaded version, as again, no parallel processing is occurring. The final iteration runs in a multi threaded manner by simply setting the block configuration (ExecutionDataFlowBlockOptions) property of MaxDegreeOfParallelism. What’s really amazing about these ActionBlocks is that they inherently and implicitly handle all input and output buffering and queuing by themselves. This means we can add many blocks into the processing pipeline at a faster rate than they can be executed, and the TPL will handle the queuing for us.
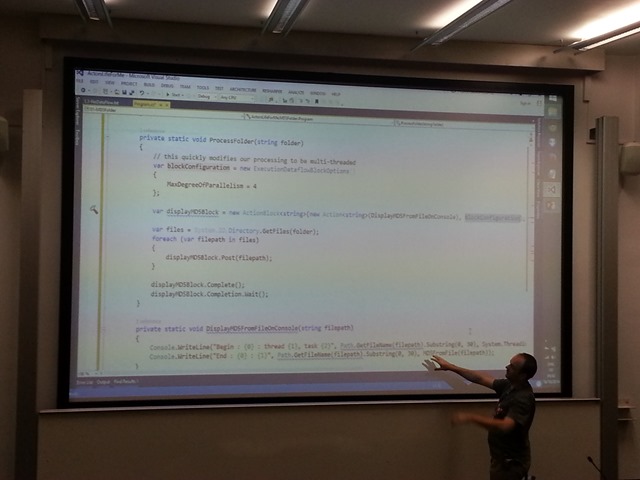
Liam next talks about separating the processing and calculating of the file hashes by performing these in a TransformBlock rather than an ActionBlock, and only using ActionBlocks to print the hash value to the UI. The output of the TransformBlock (the hash value and the filename) is passed to the ActionBlock in the processing pipeline.
Liam then introduces the BufferBlock. This acts as a propagator between other blocks and a FIFO queue of data. Liam talks about how, in our example, we can add a BufferBlock in front of all of the TransformBlocks which will effectively evenly distribute the “load” as we provide the files to be hashed between the TransformBlocks.
Next, Liam shows how we can use the LinkTo method which allows us to filter the passing of blocks along the processing pipeline, as the LinkTo method allows us to pass a predicate to perform the filtering. This could be used (for example) to hash files of different types by different TransformBlocks (i.e. an MP3 file is processed differently than an MP4 file etc.). Liam also introduces the TransformManyBlock which takes an IEnumerable of things to process. This means we no longer have to have our own loop through each of the files to be processed, instead, we can simply pass in the contents of the folder’s files as a complete IEnumerable collection.
Finally, Liam mentions both the BroadcastBlock and the BatchBlock. The Broadcast block is effectively a pub/sub mechanism as used in Message Buses etc. which allows fanning-out of the messages and broadcasting to other blocks. The BatchBlock allows batching of inputs before passing the messages along the processing pipeline.
All in all, Liam’s talk was very informative and shows just how far we’ve come in our ability to relatively easily and simply perform parallel processing in a multi-threaded manner, taking advantage of all of the cores available to us on a modern day machine. Liam’s demo code has been made available on GitHub for those interested in learning more.

The next talk is Ian Cooper’s “Not Just Layers! – What can pipelines and events do for you?”, which is a talk about Data Flow Architectures, and specifically Pipelines and Events. Ian first talks about general software architecture and how processes evolve from basic application of a skill through to adoption of genuine craftsmanship and best-practices. Software Architecture has many styles, but a single style can be explained as a series of component and connectors. Components are the individual parts of an architecture that does something and the connectors are how multiple components talk to each other.
Ian states that Data Flow architectures are more driven by behaviour rather than state, and says that functional languages (such as F#) are better suited to behaviourally modelled architecture, whereas object oriented (OO) languages like C# are better suited to solve state driven processes and architectures.
Ian uses the KWIC (Keyword in context) algorithm, which is how Unix indexes text in its man pages, as the reference for the session.
Ian talks about pipes and filters, and states that it’s a flow of data processing along a pipeline of specific stages. A push pipeline “pushes” tasks along the pipeline, the pipeline usually consisting of a pump at the front, which pushes data into the pipeline, with a series of filters which are the processing tasks and with each preceding filter responsible for pushing the data to the succeeding filter in the pipeline. There’s also usually a sink at the end that provides the final end result. There’s also Pull pipelines, of which .NET’s LINQ is an example, which have each filter further along the pipeline doing the pulling of the data from the previous filter, rather than the previous filter pushing the data on.
Ian mentions how pipes and filters architecture is similar to a batch sequence architecture (See below for the subtle difference between them). He talks about how errors that may happen in a long-running sequence that need the entire processing stream to be undo are better suited to a batch sequence architecture than a pipes and filter architecture, due to the more disconnected nature of the pipes and filter architecture.
Ian talks about parallel execution and the potential pub/sub problem of consumers awaiting data and not knowing when the entire workload is completed. If individual steps are either faster or slower than the preceding or succeeding steps in the chain, this can cause problems with either no data, or too much data to process. The solution to this problem is to introduce a “buffer” in between steps within the chain. Such things as Message Queues (i.e. MSMQ, RabbitMQ etc) or in-memory caching mechanisms (such as those provided by tools like Redis) can offer this.
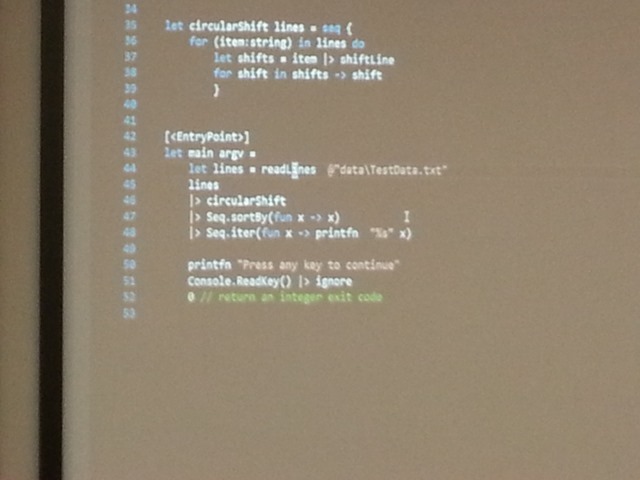
Ian then show us an in-memory demo of a program using the pipes and filters architecture. Ian states that, ideally, filters in a pipeline shouldn’t really know about other filters, but its okay for them to be aware of an abstraction of a new filter that’s next in the pipeline, but not the concrete instance of that filter. Ian uses the KWIC algorithm for the demo code. Ian shows the same demo using the manual pipeline and filters, and also a LINQ implementation. The LINQ example has its filters implemented as fluent method calls simply chained together (i.e. TextLines.Shift(x=>x).RemoveNoise(x => x).Sort() etc.). Ian then show the same example as written in F#. This shows the pipeline, using F#’s pipeline operator “|>” is even simpler to see from the code that implements it.
Ian shows us the demo code using a message queue (using MSMQ behind the scenes), this shows a pull based pipeline where each filter down the chain pulls messages from a message queue to which messages are posted by the preceding filter in the pipeline chain. Ian also shows us the pipeline running in a parallel manner, using the Task Parallel Library. Each filter has distinct Inputs and Outputs defined as BlockingCollection<T> allowing the data to flow in and out, but to be blocked on the individual thread if the next filter in the pipeline isn’t ready to receive that data.
Finally, Ian talks about Batch Sequences and how they differ slightly from a pipes and filters architecture. He talks about how you did Batch Sequencing many years ago with magnetic tapes being passed from one reel-to-reel processing machine to the next! The main difference between Batch Sequence and Pipes and Filters is that in a batch sequence, each filter has to complete the entire workload of data before passing everything as output to the next filter in the chain. By contrast, pipes and filters will have its filter only process one small piece of work or one individual piece of data before passing it down the processing chain. This means that true pipes and filters is much better suited to being parallelized than a batch sequence architecture.

The next session is Richard Tasker’s “BDD and why you should be doing it”. Richard starts by introducing BDD (Behaviour Driven Development) and where it originated. It was first proposed by Dan North as a “solution” to some of the failings of TDD such as: Where do you start with TDD? What to test and what not to test? and How much to test in one go?
Richard starts by talking about his first exposures to understanding BDD. This started with writing expressive names for standard unit tests. This helps understand what the test is testing and thus, what the code is doing. I.e. the expression of a behaviour of the code. It’s from here that we can see how we can make the mental leap from testing and exercising small methods of of code, but a more user-centric behaviour of the overall application.
Richard shows a series of Database Entity Relationship diagrams as the first mechanism he used to design an application used to model car parts and their relation to vehicles. This had to go through a number of iterations to fully realise the entities involved and their relationships to each other and it wasn’t the most effective way to achieve the overall design. Using a series of User Stories which could be turned into BDD tests was the way forward.
Richard next introduced the MoSCoW method as the way in which he started writing his BDD tests. Using this method combined with the new style of user story templates emphasises the behaviour and business function. Instead of writing “As a (type of user) I want (some functionality) so that (some benefit)”, we instead write, “In order to (achieve some value), as a (type of user), I should have (some functionality)”. The last part of the user story gets the relevant must/should/could/won’t wording in order to help achieve effective prioritization with the customer.
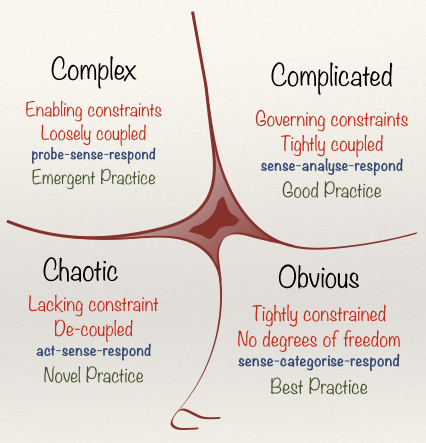
Richard then introduces SpecFlow as his BDD tool of choice. He shows a simple demo of a single SpecFlow acceptance test, backed by a number of standard unit tests. Richard says that you probably don’t want to do this for every individual tiny part of your application as this can lead to an abundance of unit tests and further lead to a test maintenance burden. To help solve this, Richard talks about Decision Frameworks, of which a popular one is called “Cynefin”. It defines states of Obvious, Chaotic, Complex and Complicated. Each area of the application and discrete pieces of functionality can be assessed to see which of the four Cynefin states they may fall into. From here, we can decide how many or how few BDD Acceptance tests are best utilised for that feature to deliver the best return on investment. Richard says that Acceptance tests are often best used in Complicated & Complex states, but are often less useful in Obvious & Chaotic states.
Richard closes his session with “why” we should be doing BDD. He talks about many of the benefits of adopting BDD and says that it is a great helper for teams that are new to TDD. Richard says that BDD helps to reduce communication barriers between the developers and other technical professionals and the perhaps less technical business stakeholders and that BDD also helps with prioritizing which features should be implemented before others. BDD also helps with naming things and defining the specific behaviours of our application in a more user-oriented way and also helps to define the meaning of “done”.

After Richard’s talk, it was lunchtime. Lunch was served in the same communal area where we’d all gathered earlier at breakfast time and consisted to a rather nice sandwich, a bag of crisps and a drink. It was nice that all three ingredients could be chosen by each individual attendee from a selection available.

After enjoying this very nice lunch, I decided to skip the Grok talks (these are short, 10 minute talks that generally happen over lunchtime at the various DDD conferences) and get some fresh air outside. That didn’t last too long, as I found the Pack Horse pub just down the road from the area of the university used for the conference. This is a pub belonging to a small local microbrewery called The Burley Street Brewhouse. I decided I had to go in and sneak a cheeky pint of bitter as a lunchtime treat. It was indeed a lovely pint and afterwards, I headed back to the university and to the DDD North conference. I went back in via an entrance close to the communal area still housing some conference attendees and realised that a number of sandwiches and crisps were still available for any attendee that wanted 2nd helpings! I was still a bit peckish after my liquid refreshment (and knowing that I wouldn’t be eating until quite late in the evening at the after conference Geek Dinner) I decided to go for seconds! After enjoying my second helpings, I headed off for the first session of the afternoon.

The first afternoon session is Andrew MacDonald’s “CQRS & Event Sourcing”. Andrew first talks about the how & why of starting development in a brand new project. Andrew has his own development project, treevue.com, for which he decided to try out CQRS and event sourcing as they were two new interesting techniques that Andrew believed could help with the development of his software. treevue.com is a web product which offers virtual data rooms. Andrew talks about the benefits of CQRS & Event sourcing such as allowing a truly abstracted data storage model, providing domain driven design without noise and that separating reads and writes to the data model via CQRS could open up new possibilities for the software. Andrew states that it’s not appropriate for everything and quotes Udi Dahan who said that most people who have used CQRS shouldn’t have done so!
CQRS is Command Query Responsibility Segregation and allows commands (processes that alter our data) to be separate from and entirely distinct from Queries (processes that only read our data but don’t change it). The models behind each of these can be entirely different, even when referring to the same domain entities, so a data model for reading (for example) a Customer type can have a different design when reading than when writing.
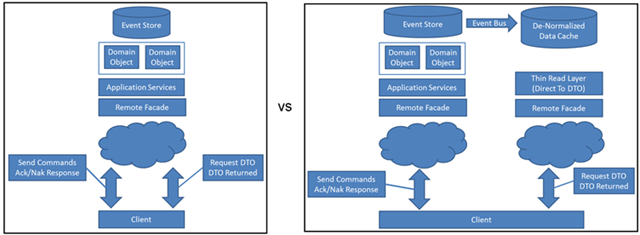
Andrew talks about the overall architecture of a system that employs CQRS vs. one that doesn’t. Without CQRS, reads and writes flow through the same layers of our application. With CQRS, we can have entirely different architectures for reading vs. writing. Usually the writing architecture is similar to the entire non-CQRS architecture, flowing through many layers including data access, validation layers etc., but often the reading architecture uses a much flatter set of layers to read the data as concerns such as validation are generally not required in this context. The two separate reading and writing stacks can often even connect to separate databases which provide “eventual consistency” with each other. This also means reading and writing can scale independently of each other, and given that many apps read far more than write, this can be invaluable.
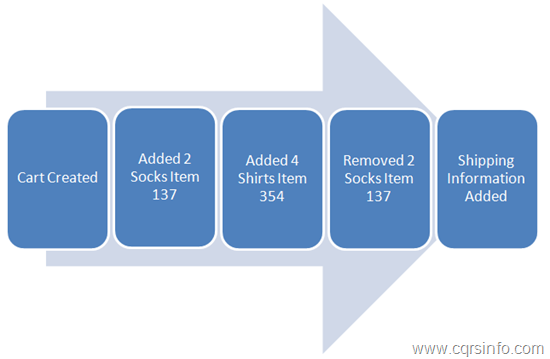
Andrew then introduces Event Sourcing which, whilst separate and different from CQRS, does play well with it. Andrew shows a typical relational model of a purchase order with multiple purchase order line item types related to it and a separate shipping info type attached. This model only allows us to see the state of the order and its data as it stands right now. Event sourcing shows the timeline of events against the purchase order as each alteration to the entity is stored separately in an event queue/database. i.e. A line item is added with an (incorrect) quantity of 4. But corrected with a later event deducting 2 from the line item, leaving a line item with a correct quantity of 2. This provides us with the ability to not only see how the data looks “right now”, but to be able to create the entire state of the entity model at any given point in time.
Andrew then proceeds to talk about Azure’s role in his treevue app and how he’s utilised Azure’s Table Storage as a first class citizen. He then shows us a quick demo and some code using EventProcessors and CommandProcessors which effectively implement the CQRS pattern.
Finally, Andrew shows how he uses something called a “snapshot” when reading domain aggregates, which is effectively a caching layer used to improve performance around building the domain aggregate models from the various events that make up a specific state of the model as at a certain point in time. This is particularly important when running applications in the cloud and using such technology as Azure Table Storage, as this will only serve back a maximum of 1000 rows per query before you, as the developer, have to make further requests for more data. Andrew points out that the demo code is available on GitHub for those interested in diving deeper and learning more from his own implementation.

The final session for today is David Whitney’s “Lessons Learnt running a public API”. David is a freelance consultant who has worked for many companies writing large public API’s. The company used for reference during David’s talk is the work he did with Just Giving. David states how the project to build the Just Giving API grew so large that the API eventually became the company’s biggest revenue stream.
David’s talk is a fast-paced set of tips, tricks and lessons that he has personally learned over the many years working with clients developing their large public-facing API’s.
David starts with stating that your API is your public facing contract to the world, and that it will live or die by the strength of it’s documentation. If it’s bad, people will write bad implementations, and you can’t blame them when that happens. Documentation for APIs can either be created first, which then drives the design of the API, or it can be performed the other way around, where you write the API first and document it afterwards. Either approach is viable, so long as documentation does indeed exist and is sufficiently comprehensive to allow your consumers to build quality implementations of your API. David says it’s often best to host the docs with the API itself so that if you hit the API endpoint with a web browser as a human user, you’ll serve up the API documentation.
David states that the DTO’s returned from API calls should provide “examples” of themselves. This is a simple mechanism that lets users “discover” your API and helps them to understand just how they should use it. Code such as this:
public interface IProvideAnExampleOf<TMyself>
{
ExampleOf<TMyself>[] BuildExample();
}
public class ExampleOf<T>
{
public string Description { get; set; }
public T Example { get; set; }
public ExampleOf(string description, T example)
{
Description = description;
Example = example;
}
}
will enable your API to provide examples of itself to your users. David states that anything you can do to help your API consumers will greatly cut down the inevitable avalanche of help requests that will hit you.
Following on from individual examples, it’s good to have your API and it’s documentation provide “recipes” for how to use large sections of your API and how to call discrete service endpoints in a coherent chain in order to achieve a specific outcome. Recipes help your users to “fall into the pit of success”. Providing things like a complete web application, ideally written in multiple languages, that exercises various parts of your API is even better.
David next talks about versioning of your API, and says that it’s something you have to ensure you have a policy on from Day 1. Retrofitting versioning is very hard and often leads to broken or awkward implementations. Adding version numbers to the URI is perhaps the easiest to achieve, but it’s not really the best approach. It’s far better to add the API version in the HTTP header.
He continues by talking about modifying existing API calls. Don’t. Just don’t do it at any cost! If you really must, you can add additional data to the return values of your API endpoints, but you must never change or remove anything that’s already there. You must also never rename anything. If you need to do any of this, use a new version. This leads into Content Types, and here David states that you’ll really need to provide all the different content types that people will realistically use. Whilst many web developers today see JSON as the de-facto standard, many companies – especially large enterprises – are still using XML as their de-facto standard. Your API is going to have to support both. David also mentions that JSONP is another, growing, standard that you may well have to support, but be careful if you do as you’ll need to be mindful of possible errors caused by CORS (Cross Origin Resource Sharing) which is the ability of resources such as JavaScript to be able to be called from domains other than the one where the resource is hosted.
David talks about the importance of making Statistics for your API available and public. You need to ensure you’re gathering performance and other statistics on every method call. One possibility is returning some statistics back to the consumer directly in the HTTP response header after every request to your API, such as the server name that serviced the consumer’s request. This is especially useful if you’ve got a large server farm and need help debugging service call issues. Also you should ensure you publically expose your statistics in a dashboard via status updates, uptime pages and more. For one, it’ll help you deflect any criticisms that your performance is broken, and it’ll provide consumers with confidence that your API is up, that it stays up and that you’re on top of maintaining this. (Unless, of course, your performance really is broken in which case that same fancy dashboard will help you have visibility into diagnosing and correcting the issue!). David next mentions the importance of a good staging server for user testing. Don’t simply expose an internal “test” server that you may have cobbled together. David relates first hand experience of just how difficult it can be getting users to stop using your “test” server after you’ve allow them access!

The next part of the session focuses on the overall approach to design of your API. David stresses that it’s good to go back and read the original documentation on RESTful architecture, written by Roy Fielding as a doctoral dissertation back in the year 2000. Further, it’s important to lean on existing conventions – always return canonical URI’s rather than relative ones and always supply ID’s and URI’s when returning data that refers to any domain or service entity. As well as ensuring you follow existing standards, it’s also important to investigate new, emerging standards too. Standards such as HAL (Hypertext Application Language) and JSON API can ensure that should such standards quickly become mainstream, you can adapt your API to support them.
David continues his session by talking about the cardinal sins of API design. First thing you must never do is this:
{
"PageType": 1,
"SomeText": "This is some text"
}
What, exactly, is PageType 1? We’re talking, of course, about magic numbers. Don’t do it. This forces your consumers to go off and look it up in the documentation, and whilst that documentation should definitely exist, there’s no reason why you can’t provide a more meaningful value to your consumer. You have to think like a consumer at all times and try to imagine the applications they’re going to build using your API. Also, don’t ever ask a user for data that your API itself can’t supply – i.e. Don’t ever request some specific identifier for a resource if you don’t provide that identifier when returning that resource in other requests. Build your services RESTfully, don’t build XML-RPC with SOAP envelopes. Be resource oriented, and always ensure you use the correct HTTP verbs for all of your services actions – especially understand the difference between POST & PUT.
Make sure you understand multi-tenancy and how that will impact the design and implementation of your API. Good load balancers and proxies can balance based on request headers, so it’s really easy and useful to provide multi-tenancy in this manner. Also ensure you use a good sandbox environment for testing and don’t forget to implement good rate limiting! Users and consumers will make mistakes in their code and you don’t want them to take down your service when they do.
David talks about error handling and says you should validate everything you can when requests are made to your API. Try to return errors in batches if possible, and always make sure that error messages are useful and readable. Similar the magic numbers above, don’t return only an arcane error code to your consumers and force them to have to cross reference it from deep within your documentation.

David moves onto authentication for your API and states that this is an area that can get a bit painful. Basic HTTP Auth will get you going, and can be sufficient if your API is (and will remain) fairly small scale, however, if your API is large or likely to grow to a larger scale – and especially if your API will be used by users via third-parties, you’ll quickly grow out of Basic Auth and need something more robust. He says that OpenAuth is the best worst alternative. It provides good security but can be painful to implement. Fortunately, there are many third-party providers out there to whom you can outsource your authorisation concerns.
David then discusses providing support for your API to your users. He says the best approach is to simply put it all out there in the public domain. This provides transparency which is a good thing, but can also encourage a “self-service” model where people within the community will start to help provide answers and solutions to other community members. Something as simple as a Google Group or a tag on Stack Overflow can get you started.
David closes his session by stating that, as your API grows over time, always ensure that you’re never attempting to serve only a single customer. Keep your API clean and generic and it will remain useful to all consumers, rather than compromising that usefulness for just a minority of users. And finally, if your API is or will become a first-class product for your business, just as the Just Giving API became for them, make sure you have a full product team within your business to deal with its day to day operation and its ongoing maintenance and development. It’s all too easy to think that the API isn’t strictly a “product” due to its highly technical and slightly opaque nature, however, doing so would be a mistake.

After David’s session, we all congregated in the main lecture theatre for the wrap up presentation from Andy Westgarth, one of the conference organisers. This involved thanking the very generous sponsors of the event as without them there simply wouldn’t be a DDD conference, and it also involved a prize giving session – the prizes consisting of books, T-shirts, some Visual Studio headphones and a main prize of a Surface Pro 3!
After the excellent day, I headed to the pub which was very conveniently located immediately across the road from the venue entrance. I had a few hours to kill until the Geek Dinner which was to be held later that evening at Pizza Express in Leed’s Corn Exchange. I enjoyed a couple of pints of Leeds Pale Ale before heading off to the Pizza Express venue for my dinner.

The Geek Dinner was attended by approximately 40 people and a fantastic time was had by all. I was sat close one of the day’s earlier speakers, Andrew MacDonald, and we had a good old chin wag about past projects, work, and life as a software developer in general.
Overall, the DDD North 2014 event and the Geek Dinner afterwards was a fantastic success, and a great time was had by all. Andy promised that there’d be another one in 2015, which will be held back up in the North-East of England due to the alternating location of DDD North, so here’s looking forward to another wonderful DDD North conference in 2015.
