DDD North 2016 In Review

On Saturday, 1st October 2016 at the University of Leeds, the 6th annual DDD North event was held. After a great event last year, at the University of Sunderland in the North East, this year’s event was held in Leeds as is now customary for the event to alternate between the two locations each year.
After arriving and collecting my badge, it was a short walk to the communal area for some tea and coffee to start the day. Unfortunately, there were no bacon butties or Danish pastries this time around, but I’d had a hearty breakfast before setting off on the journey to Leeds anyway.
The first session of the day was Pete Smith’s “The Three Problems with Software Development”. Pete starts by talking about Conway’s Game of Life and how this game is similar to how software development often works, producing complex behaviours from simple building blocks. Pete says how his talk will examine some “heuristics” for software development, a sort of “series of steps” for software development best practice.

Firstly, we look at the three problems themselves. Problem Number 1 is about dividing and breaking down software components. Pete tells us that this isn’t just code or software components themselves, but can also relate to people and teams and how they are “broken down”. Problem Number 2 is how to choose effective tools, processes and approaches to your software development and Problem Number 3 is effective communication.
Looking at problem number 1 in more detail, Pete talks about “reasons for change”. He says that we should always endeavour to keep things together that need to change together. He shows an example of two simple web pages of lists of teachers and of students. The ASP.NET MVC view’s mark-up for both of these view is almost identical. As developers we’d be very tempted to abstract this into a single MVC view and only alter, using variables, the parts that differ between teachers and students, however, Pete suggests that this is not a good approach. Fundamentally, teachers and students are not the same thing, so even if the MVC views are almost identical and we have some amount of repetition, it’s good to keep them separate – for example, if we need to add specific abilities to only one of the types of teachers or students, having two separate views makes that much easier.
Nest we look at how we can best identify reasons for change. We should look at what parts of an application get deployed together, we should also look at the domain and the terminology used – are two different domain entities referred to by the same name? Or two different names for the same entity? We should consider the “ripple effect” of change – what something changes, what else has to change? Finally, the main thing to examine is logic vs intent. Logic is the code and behaviour and can (and should) be refactored and reused, however, intent should never be reused or refactored (in the previous example, the teachers and students were “intents” as they represent two entirely different things within the domain).
In looking at Problem Number 2 is more details, Pete says that we should promote good change practices. We should reduce coupling at all layer in the application and the entire software development process, but don’t over-abstract. We need to have strong test coverage for this when done in the software itself. Not necessarily 100% test coverage, but a good suite of robust tests. Pete says that in large organisations we should try to align teams with the reasons for change, however, in smaller organisations, this isn’t something that you’d need to worry about to much as the team will be much smaller anyway.
Next, Pete makes the strong suggestion that MVC controllers that do very little - something generally considered to be a good thing - is “considered harmful”! What he really means is that blanket advice is considered harmful – controllers should, generally, do as little as they need to but they can be larger if they have good reasons for it. When we’re making choices, it’s important to remain dogmatic. Don’t forget about the trade-offs and don’t get taken in by the “new shiny” things. Most importantly, when receiving advice, always remember the context of the advice. Use the right tool for the job and always read differing viewpoints for any subject to gain a more rounded understanding of the problem. Do test the limits of the approaches you take, learn from your mistakes and always focus on providing value.
In examining Problem Number 3, Pete talks about communication and how it’s often impaired due to the choice of language we use in software development. He talks about using the same names and terminology for essentially different things. For example, in the context of ASP.NET MVC, we have the notion of a “controller”, however, Angular also has the notion of a “controller” and they’re not the same thing. Pete also states how terminology like “serverless architecture” is a misnomer as it’s not serverless and how “devops”, “agile” etc. mean different things to different people! We should always say what we mean and mean what we say!
Pete talks about how code is communication. Code is read far more often than it’s written, so therefore code should be optimized for reading. Pete looks at some forms of communication and states that things like face-to-face communication, pair programming and even perhaps instant messaging are often the better forms of communication rather than things like once-a-day stand-ups and email. This is because the best forms of communication offer instant feedback. To improve our code communication, we should eliminate implicit knowledge – such as not refactoring those teacher and student views into one view. New programmers would expect to be able to find something like a TeacherList.cshtml file within the solution. Doing this helps to improve discovery, enabling new people to a codebase to get up to speed more quickly. Finally, Pete repeats his important point of focusing on refactoring the “logic” of the application and not the “intent”.
Most importantly, the best thing we can do to communicate better is to simply listen. By listening more intently, we ensure that we have the correct information that we need and we can learn from the knowledge and experience of others.

After Pete’s talk it was time to head back to the communal area for more refreshments. Tea, coffee, water and cans of coke were all available. After suitable further watering, it was time to head back to the conference rooms for the next session. This one was John Stovin’s “Thinking Functionally”.
John’s talk was held in one of the smaller rooms and was also one of the rooms located farthest away from the communal area. After the short walk to the room, I made it there with only a few seconds to spare prior to the start of the talk, and it was standing room only in the room!
John starts his talk by mentioning how the leap from OO (Object-Oriented) programming to functional programming is similar to the leap from procedural programming to OO itself. It’s a big paradigm shift! John mentions how most of today’s non-functional languages are designed to closely mimic the way the computer itself processes machine code in the “von Neumann” style. That is to say that programs are really just a big series of steps with conditions and branches along the way. Functional programming helps in the attempt to break free from this by expressing programs as pure functions – a series of functions, similar to mathematical functions, that take an input and produce an output.
John mentions how, when writing functional programs, it’s important to try your best to keep your functions “pure”. This means that the function should have no side-effects. For example a function that writes something to the console is not pure, since the side-effect is the output on the console window. John states that even throwing an exception from a function is a side-effect in itself!

We should also endeavour to always keep our data immutable. This means that we never try to assign a new value to a variable once it has already been initialized with a value – it’s a single assignment. Write once but read many. This helps us to reason about our data better as it improves readability and guarantees thread-safety of the data. To change data in a functional program, we should perform an atomic “copy-and-modify” operation which creates a copy of the data, but with our own changes applied.
In F#, most variables are immutable by default, and F# forces you to use a qualifier keyword, mutable, in order to make a variable mutable. In C#, however, we’re not so lucky. We can “fake” this, though, by wrapping our data in a type (class) – i.e. a money type, and only accepting values in the type’s constructor, ensuring all properties are either read-only or at least have a private setter. Class methods that perform some operation on the data should return a whole new instance of the type.
We move on to examine how Functional Programming eradicates nulls. Variables have to be assigned a value at declaration, and due to not being able to reassign values thanks to immutability, we can’t create a null reference. We’re stuck with nulls in C#, but we can alleviate that somewhat via the use of such techniques as the Null Object Pattern, or even the use of an Option<T> type. John continues saying that types are fundamental to F#. It has real tuple and records – which are “multiplicative” types and are effectively aggregates of other existing types, created by “multiplying” those existing types together – and also discriminating unions which are “additive” types which are created by “summing” other existing types together. For example, the “multiplicative” types aggregate or combine other types – a Tuple can contain two (or more) other types which are (e.g.) string and int, and a discriminated union, as an “additive” type, can act as the sum total of all of it’s constituent types, so a discriminated union of an int and a boolean can represent all of the possible values of an int AND all of the possible values of a boolean.
John continues with how far too much C# code is written using granular primitive types and that in F#, we’re encouraged to make all of our code based on types. So, for example, a monetary amount shouldn’t be written as simply a variable of type decimal or float, but should be wrapped in a strong Money type, which can enforce certain constraints around how that type is used. This is possible in C# and is something we should all try to do more of. John then shows us some F# code declaring an F# discriminated union:
type Shape =
| Rectangle of float * float
| Circle of float
He states how this is similar to the inheritance we know in C#, but it’s not quite the same. It’s more like set theory for types!

John continues by discussing pattern matching. He says how this is much richer in F# than the kind-of equivalent if() or switch() statements in C# as pattern matching can match based upon the general “shape” of the type. We’re told how functional programming also favours recursion over loops. F#’s compiler has tail recursion, where the compiler can re-write the function to pass additional parameters on a recursive call and therefore negate the need to continually add accumulated values to the stack as this helps to prevent stack overflow problems. Loops are problematic in functional programming as we need a variable for the loop counter which is traditionally re-assigned to with every iteration of the loop – something that we can’t due in F# due to variable immutability.
We continue by looking at lists and sequences. These are very well used data structures in functional programming. Lists are recursive structures and are either an empty list or a “head” with a list attached to it. We iterate over the list by taking the “head” element with each pass – kind of like popping values off a stack. Next we look at higher-order functions. These are simply functions that take another function as a parameter, so for example, virtually all of the LINQ extension methods found in C# are higher-order functions (i.,e. .Where, .Select etc.) as these functions take a lambda function to act as a predicate. F# has List and Seq and the built-in functions for working with these are primarily Filter() and Map(). These are also higher-order functions. Filter takes a predicate to filter a list and Map takes a Func that transforms each list element from one type to another.
John goes on to mention Reactive Extensions for C# which is a library for composing asynchronous and event-based programs using observable sequences and LINQ-style query operators. These operators are also higher-order functions and are very “functional” in their architecture. The Reactive Extensions (Rx) allow composability over events and are great for both UI code and processing data streams.

John then moves on to discuss Railway-oriented programming. This is a concept whereby all functions both accept and return a type which is of type Result<TSuccess, TFailure>. All functions return a Result<T,K> type which “contains” a type that indicates either success or failure. Functions are then composable based upon the types returned, and execution path through code can be modified based upon the resulting outcome of prior functions.
Using such techniques as Railway-oriented programming, along with the other inherent features of F#, such as a lack of null values and immutability means that frequently programs are far easier to reason about in F# than the equivalent program written in C#. This is especially true for multi-threaded programs.
Finally, John recaps by stating that functional languages give a level of abstraction above the von Neumann architecture of the underlying machine. This is perhaps one of the major reasons that FP is gaining ground in recent years as machine are now powerful enough to allow this (previously, old-school LISP programs – LISP being one of the very first functional languages originally design back in 1958 - often used purpose built machines to run LISP sufficiently well). John recommends a few resources for further reading – one is the F# for Fun and Profit website.
After John’s session, it was time for a further break and additional refreshment. Since John’s session had been in a small room and one which was farthest away from the communal area where the refreshments where, and given that my next session was still in this very same conference room, I decided that I’d stay where I was and await the next session, which was Matteo Emili’s “I Read The Phoenix Project And I Loved It. Now What?”

Matteo’s session was all about introducing a “devops” culture into somewhere that doesn’t yet have such a culture. The Phoenix Project is a development “novel” which tells a story of doing just such a thing. Matteo starts by mentioning The Phoenix Project book and how it’s a great book. I must concur that the book is very good, having read it myself only a few weeks before attending DDD North. Matteo that asks that, if we’d read the book and would like to implement it’s ideas into our own places of work, we should be very careful. It’s not so simple, and you can’t change an entire company overnight, but you can start to make small steps towards the end goal.
There are three critical concepts that cause failure and a breakdown in an effective devops culture. They are bottlenecks, lack of communication and boundaries between departments. In order to start with the introduction of a devops culture, you need to start “out-of-band”. This means you’ll need to do something yourself, without the backing of your team, in order to prove a specific hypothesis. Only when you’re sure something will work should you then introduce the idea to the team.
Starting with bottlenecks, the best way to eliminate them is to automate everything that can be automated. This reduces human error, is entirely repeatable, and importantly frees up time and people for other, more important, tasks. Matteo reminds us that we can’t change what we can’t measure and in the loop of “build-measure-learn”, the most important aspect is measure. We measure by gathering metrics on our automations and our process using logging and telemetry and it’s only from these metrics will we know whether we’re really heading in the right direction and what is really “broken” or needs improvement. We should gather insights from our users as well by utilising such tools and software as Google Analytics, New Relic, Splunk & HockeyApp for example. Doing this leads to evidence based management allowing you to use real world numbers to drive change.

Matteo explains that resource utilisation is key. Don’t bring a whole new change management process out of the blue. Use small changes that generate big wins and this is frequently done “out-of-band”. One simple thing that can be done to help break down boundaries between areas of the company is a company-wide “stand up”. Do this once a week, and limit it to 1-2 minutes per functional area. This greatly improves communication and helps areas understand each other better. The implementation of automation and the eradication of boundaries form the basis of the road to continuous delivery.
We should ensure that our applications are properly packaged to allow such automation. MSDeploy is such a tool to help enable this. It’s an old technology, having first been released around 2003, but it’s seeing a modern resurgence as it can be heavily utilised with Azure. Use an infrastructure-as-code approach. Virtual Machines, Servers, Network topology etc. should all be scripted and version controlled. This allows automation. This is fair easy to achieve with cloud-based infrastructure in Azure by using Azure ARM or by using AWS CloudFormation with Amazon Web Services. Some options for achieving the same thing with on-premise infrastructure are Chef, Puppet or even Powershell Desired State Configuration. Databases are often neglected with regard to DevOps scenarios, however, by using version control and performing small, incremental changes to database infrastructure and the usage of packages (such as SQL Server’s DACPAC files), this can help to move Database Lifecycle Management into a DevOps/continuous delivery environment.
This brings us to testing. We should use test suites to ensure our scripts and automation is correct and we must remember the golden rule. If something is going to fail, it must fail fast. Automated and manual testing should be used to ensure this. Accountability is important so tests are critical to the product, and remediation (recovery from failure) should be something that is also automated.
Matteo summarises, start with changing people first, then change the processes and the tools will follow. Remember, automation, automation, automation! Finally, tackle the broader technical side and blend individual competencies to the real world requirements of the teams and the overall business.

After Matteo’s session, it was time for lunch. All of the attendees reconvened in the communal area where we were treated to a selection of sandwiches and packets of crisps. After selecting my lunch, I found a vacant spot in the corner of the rather small communal area (which easily filled to capacity once all of the different sessions had finished and all of the conference’s attendees descending on the same space) to eat it. Since lunch break was 1.5 hours and I’d eaten my lunch within the first 20 minutes, I decided to step outside to grab some fresh air. It was at this point I remembered a rather excellent little pub just 2 minutes walk down the road from the university venue hosting the conference. Well, never one to pass up the opportunity of a nice pint of real ale, I heading off down the road to The Pack Horse.

Once inside, I treated myself to lovely pint of Laguna Seca from a local brewery, Burley Street Brewhouse, and settled down in the quiet pub to enjoy my pint and reflect on the morning’s sessions. During the lunch break, there are usually some grok talks being held, which are are 10-15 minute long “lightning” talks, which attendees can watch whilst they enjoy their lunch. Since DDD North was held very close to the previous DDD Reading event (only a matter of a few weeks apart) and since the organisers were largely the same for both events, I had heard that the grok talks would be largely the same as those that had taken place, and which I’d already seen, at DDD Reading only a matter of weeks prior. Due to this, I decided the pub was a more attractive option over the lunch time break!
After slowly drinking and savouring my pint, it was time to head back to the university’s mechanical engineering department and to the afternoon sessions of DDD North 2016.
The afternoon’s first session was, luckily, in one of the “main” lecture halls of the venue, so I didn’t have too far to travel to take my seat for Bart Read’s “How To Speed Up .NET & SQL Server Apps”.
Bart’s session is al about performance. Performance of our application’s code and performance of the databases that underlie our application. Bart starts by introducing himself and states that, amongst other things, he was previously an employee of Red Gate, who make quite a number of SQL Server tools so paying close attention to performance monitoring in something that Bart has done for much of his career.

He states that we need to start with measurement. Without this, we can’t possibly know where issues are occurring within our application. Surprisingly, Bart does say that when starting to measure a database-driven application, many of the worst areas are not within the code itself, and are almost always down in the database layer. This may be from an errant query or general lack of helpful database additions (better indexes etc.)
Bart mentions the tools that he himself uses as part of his general “toolbox” for performance analysis of an application stack. ANTS Memory Profiler from Red Gate will help analyse memory consumption issues. dotMemory from JetBrains is another good choice in the same area. ANTS Performance Profiler from Red Gate will help analyse the performance of .NET code and monitor it’s CPU consumption. Again, JetBrains have dotTrace in the same space. There’s also the lesser known .NET Memory Profiler which is a good option. For network monitoring, Bart uses Wireshark. For general testing tools, Bart recommends BlazeMeter (for load testing) and Neustar.
Bart also stresses the importance of the ongoing usage of production monitoring tools. Services such as New Relic, AppDynamics etc. can provide ongoing metrics for your running application when it’s live in production and are invaluable to understand exactly how your application is behaving in a production environment.
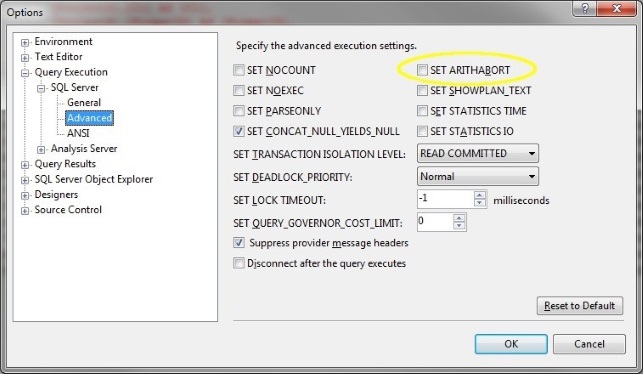
Bart shares a very handy tip regarding usage of SQL Server Management Studio for general debugging of SQL Server queries. He states that we should always UNCHECK the SET ARITHABORT option inside SSMS’s options menu. Doing this prevents SQL Server from aborting any queries that perform arithmetic overflows or divide-by-zero operations, meaning that your query will continue to run, giving you a much clearer picture of what the query is actually doing (and how long it takes to run).
From here, Bart shares with us 3 different real-world performance scenarios that he has been involved in, how he went about diagnosing the performance issues and how he fixed them.
The first scenario was helping a client’s customer support team who were struggling as it was taking them 40 seconds to retrieve one of their customer’s details from their system when on a support phone call. The architecture of the application was a ASP.NET MVC web application in C# and using NHibernate to talk to 2 different SQL Server instances - one server was a primary and the other, a linked server.
Bart started by using ANTS Performance Profiler on the web layer and was able to highlight “hotspots” of slow running code, precisely in the area where the application was calling out to the database. From here, Bart could see that one of the SQL queries was taking 9 seconds to complete. After capturing the exact SQL statement that was being sent to the database, it was time to fire up SSMS and use SQL Server Profiler in order to run that SQL statement and gain further insight into why it was taking so long to run.

After some analysis, Bart discovered that there was a database View on the primary SQL Server that was pulling data from a table on the linked server. Further, there was no filtering on the data pulled from the linked server, only filtering on the final result set after multiple tables of data had been combined. This meant that the entire table’s data from the linked server was being pulled across the network to the primary server before any filtering was applied, even though not all of the data was required (the filtering discarded most of it). To resolve the problem, Bart added a simple WHERE clause to the data that was being selected from the linked server’s table and the execution time of the query went from 9 seconds to only 100 milliseconds!
Bart moves on to tell us about the second scenario. This one had a very similar application architecture as the first scenario, but the problem here was a creeping increase in memory usage of the application over time. As the memory increased, so the performance of the application decreased and this was due to the .NET garbage collector having to examine more and more memory in order to determine which objects to garbage collect. This examination of memory takes time. For this scenario, Bart used ANTS Memory Profiler to show specific objects that were leaking memory. After some analysis, he found it was down to a DI (dependency injection) container (in this case, Windsor) having an incorrect lifecycle setting for objects that it created and thus these objects were not cleaned up as efficiently as they should have been. The resolution was to simply configure the DI container to correctly dispose of unneeded objects and the excessive memory consumption disappeared.

From here, we move onto the third scenario. This was a multi-tenanted application where each customer had their own database. It was an ASP.NET Web application but used a custom ADO layer written in C++ to access the database. Bart spares us the details, but tells us that the problem was ultimately down to locking, blocking and deadlocking in the database. Bart uses this to remind us of the various concurrency levels in SQL Server. There’s object level concurrency and row level concurrency, and when many people are trying to read a row that’s concurrently being written to, deadlocks can occur. There’s many different solution available for this and one such solution is to use a READ COMMITED SNAPSHOT isolation level on the database. This uses TempDB to help “scale” the demands against the database, so it’s important that the TempDB is stored on a fast storage medium (a fast SSD drive for example). The best solution is a more disciplined ordering of object access and this is usually implemented with a Unit Of Work pattern, but Bart tells us that this is difficult to achieve with SQL Server.
Finally, Bart tells us all about scenario number four. The fundamental problem with this scenario was networking, and more specifically it was down to network latency that was killing the application’s performance. The application architecture here was not a problem as the application was using Virtual Machines running on VMWare’s vSphere with lots and lots of CPU and Memory to spare. The SQL Server was running on bare metal to ensure performance of the database layer. Bart noticed that the problem manifested itself when certain queries were run. Most of the time, the query would complete in less than 100ms, but occasionally spikes of 500-600ms could be seen when running the exact same query. To diagnose this issue, Bart used WireShark on both ends of the network, that is to say on the application server where the query originated and on the database server where the data was stored, however, as soon as Wireshark was attached to the network, the performance problem disappeared!
This ultimately turned out to be an incorrect setting on the virtual NIC as Bart could see the the SQL Server was sending results back to the client in only 1ms, however, it was a full 500ms to receive the results when measured from the client (application) side of the network link. It was disabling the “receive side coalescing” setting that fixed the problem. Wireshark itself temporarily disables this setting, hence the problem disappearing when Wireshark was attached.

Bart finally tells us that whilst he’s mostly a server-side performance guy, he’s made some general observations about dealing with client-side performance problems. These are generally down to size of payload, chattiness of the client-side code, garbage collection in JavaScript code and the execution speed of JavaScript code. He also reminds us that most performance problems in database-driven applications are usually found at the database layer, and can often be fixed with simple things like adding more relevant indexes, adding stored procedures and utilising efficient cached execution plans.
After Bart’s session, it was time for a final refreshment break before the final session of the day. For me, the final session was Gary McClean Hall’s “DDD: the God That Failed”
Gary starts his session by acknowledging that the title is a little clickbait-ish as his talk started life as a blog post he had previously written. His talk is all about Domain Driven Design (DDD) and how he implemented DDD when he was working within the games industry. Gary mentions that he’s the author of the book, “Adaptive Code via C#” and that when we he was working in the game industry, he had worked on the Championship Manager 2008 game.
Gary’s usage of DDD in game development started when there was a split between two companies involved in the Championship Manager series of games. In the fall out of the split, one company kept the rights to the name, and the other company kept the codebase! Gary was with the company that had the name but no code and they needed to re-create the game, which had previously been many years in development, in a very compressed timescale of only 12 months.

Gary starts with a definition of DDD. It is modelling for complicated domains. Gary is keen to stress the word “complicated”. Therefore, we need to be able to identify what exactly is a complicated domain. In order to help with this, it’s often best to create a “DDD Maturity Model” for the domain in which we’re working. This is a series of topics which can be further expanded upon with the specifics for that topic (if any) within out domain. The topics are:
- The Domain
- Domain Entity Behaviour
- Decoupled Domain
- Aggregate Roots
- Domain Events
- CQRS
- Bounded Contexts
- Polyglotism
By examining the topics in the list above and determining the details for those topics within our own domain, we can evaluate our domain and it’s relative complexity and thus its suitability to be modelled using DDD.

Gary continues by showing us a typical structure of a Visual Studio solution that purports to follow the Domain Driven Design pattern. He states that he sees many such solutions configured this way, but it’s not really DDD and usually represent a very anaemic domain. Anaemic domain models are collections of classes that are usually nothing more than properties with getters and setters, but little to no behaviour. This type of model is considered an anti-pattern as they offer very low cohesion and high coupling.
If you’re working with such a domain model, you can start to fix things. Looking for areas of the domain that can benefit from better types rather than using primitive types is a good start. A classic example of this is a class to represent money. Having a “money” class allows better control over the scale of the values you’re dealing with and can also encompass currency information as well. This is preferable to simply passing values around the domain as decimals or ints.
Commonly, in the type of anaemic domain model as detailed above, there are usually repositories associated with entity models within the domain, and it’s usually a single repository per entity model. This is also considered an anti-pattern as most entities within the domain will be heavily related and thus should be persisted together in the same transaction. Of course, the persistence of the entity data should be abstracted from the domain model itself.
Gary then touches upon an interested subject, which is the decoupling within a DDD solution. Our ASP.NET views have ViewModels, our domain has it’s Domain Models and the persistence (data) layer has it’s own data models. One frequent piece of code plumbing that’s required here is extensive mapping between the various models throughout the layers of the application. In this regard, Gary suggests reading Mark Seemann’s article, “Is layering worth the mapping?” In this article, Mark suggests that the best way to avoid having to perform extensive mapping is to move less data around between the layers of our application. This can sometimes be accomplished, but depending upon the nature of the application, this can be difficult to achieve.

So, looking back at the “repository-per-entity” model again, we’re reminded that it’s usually the wrong approach. In order to determine the repositories of our domain, we need to examine the domain’s “Aggregate Roots”. A aggregate root is the top-level object that “contains” additional other child objects within the domain. So, for example, a class representing a Customer could be an aggregate root. Here, the customer would have zero, one or more Order classes as children, and each Order class could have one or more OrderItems as children, with each OrderItem linking out to a Product class. It’s also possible that the Product class could be considered an aggregate root of the domain too, as the product could be the “root” object that is retrieved within the domain, and the various order items across multiple orders for many different customers could be retrieved as part of the product’s object graph.
To help determine the aggregate roots within our domain, we first need to examine and determine the bounded contexts. A bounded context is a conceptually related set of objects within the domain that will work together and make sense for some of the domain’s behaviours. For example, the customer, order, orderitem and product classes above could be considered part of a “Sales” context within the domain. It’s important to note that a single domain entity can exist in more than one bounded context, and it’s frequently the case that the actually objects within code that represent that domain entity can be entirely different objects and classes from one bounded context to the next. For example, within the Sales bounded context, it’s possible that only a small subset of the product data is required, therefore the Product class within the Sales bounded context has a lot less properties/data than the Product class in a different bounded context – for example, there could be a “Catalogue” context, with the Product entity as it’s aggregate root, but this Product object is different from the previous one and contains significantly more properties/data.

The number of different bounded contexts you have within your domain determines the domain’s breadth. The size of the bounded contexts (i.e. the number of related objects within it) determines the domains depth. The size of a given bounded context’s depth determines the importance of that area of the domain to the user of the application.
Bounded contexts and the aggregate roots within them will need to communicate with one another in order that behaviour within the domain can be implemented. It’s important to ensure that aggregate roots and especially bounded contexts are not coupled to each other, so communication is performed using domain events. Domain events are an event that is raised by one aggregate root or bounded context’s entity that is broadcast to the rest of the domain. Other entities within other bounded contexts or aggregate roots will subscribe to the domain events that they may be interested in, in order for them to respond to actions and behaviour in other areas of the domain. Domain events in a .NET application are frequently modelled using the built-in events and delegates functionality of the .NET framework, although there are other options available such as the Reactive Extensions library as well as specific patterns of implementation.

One difficult area of most applications, and somewhere where the “pure” DDD model may break down slightly is search. Many different applications will require the ability to search across data within the domain, and frequently search is seen as a cross-cutting concern as the result data returned can be small amounts of data from many different aggregates and bounded contexts in one amalgamated data set. One approach that can be used to mitigate this is the CQRS – Command and Query Responsibility Segregation pattern.
Essentially, this pattern states that the models and code that we use to read data does not necessarily have to be the same models and code that we use to write data. In fact, most of the time, these models and code should be different. In the case of requiring a search across disparate data within the DDD-modelled domain, it’s absolutely fine to forego the strict DDD model and to create a specific “view” – this could be a database stored procedure or a database view – that retrieves the exact cross-cutting data that you need. Doing this prevents using the DDD model to specifically create and hydrate entire aggregate roots of object graphs (possibly across multiple different bounded contexts) as this is something that could be a very expensive operation as most of the retrieved data wouldn’t be required.
Gary reminds us that DDD aggregates can still be painful when using a relational database as the persistence storage due to the impedance mismatch of the domain models in code and the tables within the database. It’s worth examining Document databases or Graph databases as the persistent storage as these can often be a better choice.
Finally, we learn that DDD is frequently not justified in applications that are largely CRUD based or for applications that make very extensive use of data queries and reports (especially with custom result sets). Therefore, DDD is mostly appropriate for those applications that have to model a genuinely complex domain with specific and complex domain objects and behaviours and where a DDD approach can deliver real value.

After Gary’s session was over, it was time for all of the attendees to gather in the largest of the conference rooms for the final wrap-up. There were only a few prize give-aways on this occasion, and after those were awarded to the lucky attendees who had their feedback forms drawn at random, it was time to thank the great sponsors of the event, without whom there simply wouldn’t be a DDD North.
I’d had a great time at yet another fantastic DDD event, and am already looking forward to the next one!
